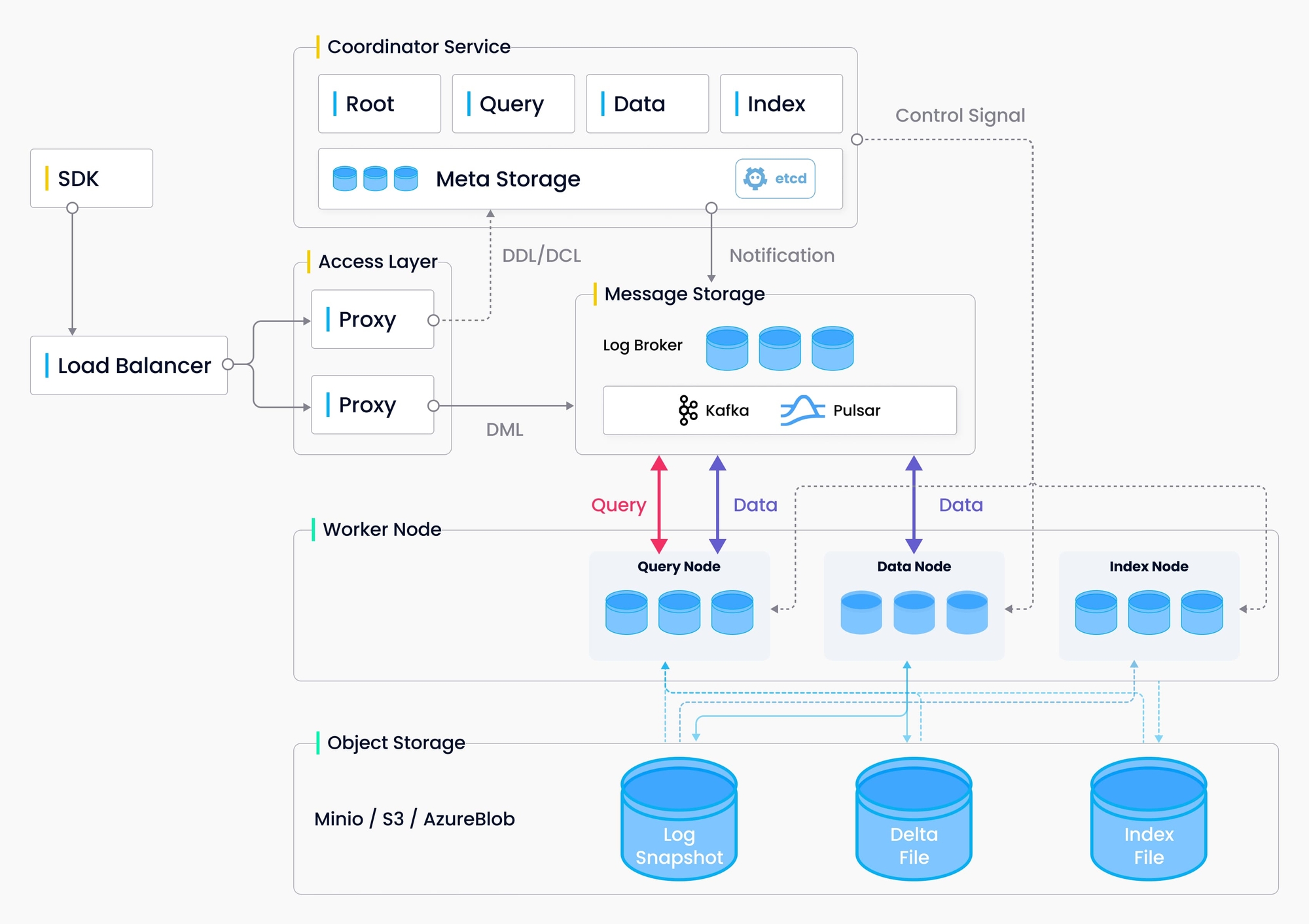
Objectives of Milvus vector database
When the idea of the Milvus vector database first came to our minds, we wanted to build a data infrastructure that could help people accelerate AI adoptions in their organizations.
Milvus in MLOps
We have set two crucial objectives for the Milvus project to fulfill this mission.
Ease of use
AI/ML is an emerging area where new technologies keep coming out. Most developers are not entirely familiar with the fast-growing technologies and tools of AI. Developers have already consumed most of their energies finding, training, and tuning the models. It’s hard for them to spend additional efforts handling the large amounts of embedding vectors generated by the models. Not to mention the manipulation of a large volume of data is always a very challenging task.
Thus we give “ease of use” a very high priority since it could significantly reduce the development cost.
Low running costs
One of the primary hurdles of AI in production is to justify the return of investment. We would have more opportunities to put our AI applications into production with lower running costs. And it would be conducive to lifting the margin of potential benefits.
Design principles of Milvus 2.0
We made a start towards these goals in Milvus 1.0. But it’s far from enough, especially in scalability and availability. Then we started the development of Milvus 2.0 to improve these points. The principles we have laid down for this new version include:
- Aiming for high scalability and availability
- Building upon mature cloud infrastructure and practice
- Minimum performance compromise in the cloud
In other words, we want to make the Milvus database cluster cloud-native.
The evolution of database clusters
The vector database is a new species of database, as it handles new types of data (vectors). But it still shares the same challenges as other databases, with some of its own requirements. In the rest of this article, I will focus on what we have learned from the existing database cluster implementations and the thinking process of how we designed the new Milvus group architecture.
If you are interested in the implementation details of Milvus group components, please stay on top of the Milvus documentation. We will continuously publish technical articles in the Milvus GitHub repo, Milvus website, and Milvus Blog.
The ideal database cluster
“Aim small, miss small.”
Let’s first list the critical capabilities an ideal database cluster should have.
- Concurrency and no single point of failure: users connected to different group members can simultaneously have read/write access to the same piece of data.
- Consistency: different group members should see the same data.
- Scalability: we can add or remove group members on the go.
Honestly, all of these capabilities are hard to acquire together. In the modern implementations of database clusters, people have to compromise some of these capabilities. People don’t expect a perfect database cluster as long as it can fit into the user scenarios. However, the shared-everything cluster was once very close to an ideal database cluster. If we want to learn something, we should start from here.
The key considerations of a database cluster
The shared-everything cluster has a more extended history compared to other modern implementations. Db2 data sharing group and Oracle RAC are typical of shared-everything clusters. Many people think shared-everything means sharing disks. It’s far more than that.
A shared-everything cluster only has one kind of database member in the group. Users could connect to any one of these symmetric members to access any data. What is “everything” that needs to be shared for making this work?
The sequence of events in the group
First, the group event sequence is crucial to resolve the potential conflicts caused by the concurrent access from different groups members. We usually use the database log record sequence number to represent the event sequence. At the same time, the log record sequence number is generally generated from the timestamp.
Thus the requirement of group event sequence is equal to the need of a global timer. If we could have an atomic clock for the group, that would be fabulous. Yet, Milvus is an open-source software project, which means we should rely on commonly available resources. To date, an atomic clock is still a premium option for large companies.
We have implemented the time synchronization component in Milvus 2.0 database cluster. You can find the link in the appendix.
Global locking
The database has a locking mechanism to resolve concurrent access conflicts, whether optimistic or pessimistic locks. Similarly, we need global locking to resolve simultaneous access conflicts across different group members.
Global locking means different group members have to talk with each other to negotiate the lock requests. Several vital factors would impact the efficiency of this global lock negotiation process:
- The speed of inter-system connections
- The number of group members who need to participate in the negotiation process
- The frequency of group conflicts
The typical group size is no more than 100. For example, Db2 DSG is 32; Oracle RAC is 100. Those group members will be placed in one server room connected with optical fiber to minimize transfer latency. That’s why it is sometimes called a centralized cluster. Due to the group size limitation, people will choose high-end servers (mainframes or minicomputers, which have much more capacity in CPU, memory, I/O channels, etc.) to consist of the shared-everything clusters.
This hardware presumption has dramatically changed in the modern cloud environment. Nowadays, cloud data centers comprise high-dense server rooms full of (thousands of) commodity X86 servers with TCP/IP connections. If we rely on these X86 servers to build the database cluster, the group size should increase to hundreds of (even thousands of) machines. And in some business scenarios, we will want these hundreds of X86 machines to spread in different regions. Thus implementing global locking might not be worth it anymore, as the global locking performance will not be good enough.
In Milvus 2.0, we are not going to implement the global locking facility. On the one hand, there is no update for vector data. (People should rather delete-then-insert instead of update.) So we don’t need to worry about the multi-writer conflicts on the same piece of data in the Milvus group with sharding arrangement. Meantime, we could use MVCC (multi-version concurrency control, a lock-avoidance concurrency control method) to resolve the reader-writer conflicts.
On the other hand, vector data processing consumes a much higher memory footprint than structured data processing. People are looking for much higher scalability in vector databases.
Shared in-memory data cache
We can briefly divide a database engine into two parts: the storage engine and the computing engine. The storage engine is responsible for two critical tasks:
- Write data to permanent storage for durability purposes.
- Load data from the permanent storage to the in-memory data cache (AKA buffer pool); this is the only place where the computing engine accesses data.
In the database cluster scenario, what if member A has updated the data cached in member B? How could member B know its in-memory data is expired? The classic shared-everything cluster has a buffer cross invalidation mechanism to resolve this issue. The buffer cross invalidation mechanism will work similarly to global locking if we maintain a strong consistency across the group members. As stated before, it is not practical in the modern cloud environment. So we decided to lower the consistency level in the Milvus cloud-scalable group to an eventual consistency manner. In this way, the buffer cross invalidation mechanism in Milvus 2.0 can be an asynchronous process.
Shared storage
Shared storage is probably the first thing people would think about when discussing a database cluster.
Storage options have also significantly changed in recent years of cloud storage evolution. The storage attached network (SAN) was (and still is) the storage foundation of the shared-everything group. But in the cloud environment, there is no SAN. The database has to use the local disk attached to the cloud virtual machines. Using local disk introduces the challenge of data consistency across the group members. And we also have to worry about the high availability of the group members.
Then Snowflake made a great role model for cloud databases using cloud shared storage (S3 storage). It inspires Milvus 2.0 too. As stated before, we intend to rely on mature cloud infrastructure. But before we could utilize cloud shared storage, we have to think about a couple of things.
First, S3 storage is cheap and reliable, but it is not designed for instant R/W access like database scenarios. We need to create the data components (which we call data nodes in Milvus 2.0) to bridge the local memory/disk and S3 storage. There are some examples (like Alluxio, JuiceFS, etc.) we could learn. The reason we can not integrate these projects directly is we focus on different data granularity. Alluxio and JuiceFS are designed for datasets or POSIX files, while we focus on the data record (vector) level.
When the vector data is settled on S3 storage, the answer for metadata is easy: store them in ETCD. How about the log data, then? In the classic implementations, the log store is also based on SAN. The log files of one database group member are shared within the database cluster for failure recovery purposes. So this was not a problem until we got into the cloud environment.
In the Spanner paper, Google illustrated how they implemented the globally-distributed database (group) with Paxos consensus algorithm. You need to program the database cluster as a state machine replication group. The redo log is usually the “state” that will be replicated across the group.
Redo-log replication by consensus algorithms is a powerful tool, and it has substantial advantages in some business scenarios. But for the Milvus vector database, we don’t find enough incentives for creating a state machine replication group as a whole. We decided to use the cloud messaging queue/platform (Apache Pulsar, Apache Kafka, etc.) as an alternative cloud shared storage for the log store. By delegating the log store to the messaging platform, we acquire the benefits below.
- The group is more event-driven, which means many processes can be asynchronous. It improves scalability.
- The components are more loosely coupled, making it much easier to perform online rolling upgrades. It improves availability and operability.
We will revisit this topic in the later section.
So far, we have wrapped up the crucial considerations of the database cluster. Before we can jump to the discussion on the Milvus 2.0 architecture, let me first explain how we manage vectors in Milvus.
Data management and performance predictability
Milvus stores vectors in collections. The “collection” is a logical concept, equivalent to a “table” in SQL databases. A “collection” could have multiple physical files to keep vectors. A physical file is a “segment”. The “segment” is a physical concept like a tablespace file in SQL databases. When the data volume is small, we can save everything in a single segment/physical file. But nowadays, we are constantly facing big data. When there are multiple segments/physical files, how should we spread the data in different data partitions?
Although data comes first rather than indexes, we have to store data in the way that the index algorithm prefers to make the data access efficiently in most cases. A frequently used strategy in SQL databases is partition by the range of partitioning key values. People usually create a clustered index to enforce the partitioning key. Overall, this is a decent approach for SQL databases. Data is stored in good shape, optimized for I/O (prefetch). But there are still defects.
- Data skew. Some of the partitions might have much more data than others. The distribution of real-world data is not as simple as the numeric range.
- Access hotspots. More workload might go to some of the data partitions.
Imagine more workload goes to partitions with more data. We need to rebalance the data across the partitions when these situations occur. (This is a DBA’s tedious daily life.)
The Clustered index for vectors
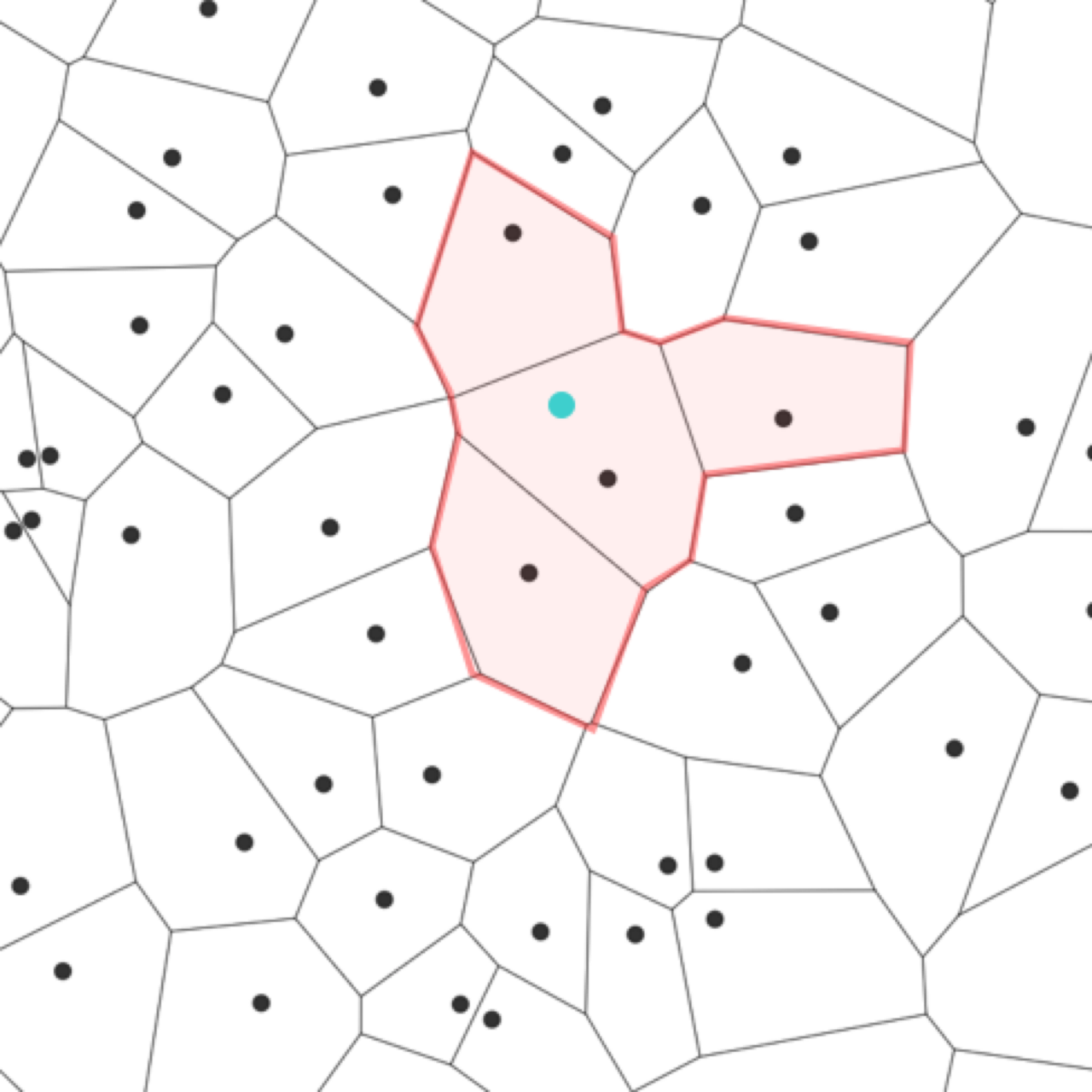
We can also create a clustered index for vectors (an inverted list index). But that is not the same case as SQL databases. Once the index is built in SQL databases, it’s very efficient to access the data through the index, with less computation and less I/O operations. But for vector data, there will be far more computation and I/O operations even with an index. So the defects mentioned before will have a more severe impact on vector database clusters. Moreover, the cost of rebalancing vectors across different segments is very high due to the data volume and computing complexity.
In Milvus, we use the strategy of partition by growth. When we inject data into a vector collection, Milvus will append the new vectors to the latest segment in the collection. Milvus will close the segment once its size is large enough (the threshold is configurable) and build the index for the closed segment. In the meantime, a new segment will be created to store the upcoming data. This simple strategy is more balanced for vector processing.
The vector query is a process to search for the most similar candidates in the vector collection. It is a typical MapReduce procedure. For example, we want to search the top 20 similar results from a vector collection with ten segments. We can search the top 20 on each one of the segments and then merge the 20 * 10 results into the final 20 results. Since each segment has the same amount of vectors and a similar index, the processing time on each segment is almost identical. It gives us the advantage of performance predictability, which is essential when planning the scale of the database clusters.
New paradigms in Milvus 2.0
In Milvus 1.0, we implemented a read/write splitting sharding group like most SQL databases. It was a good attempt at scaling the Milvus database cluster. But the problems are quite obvious too.
Milvus 1.0: sharding cluster
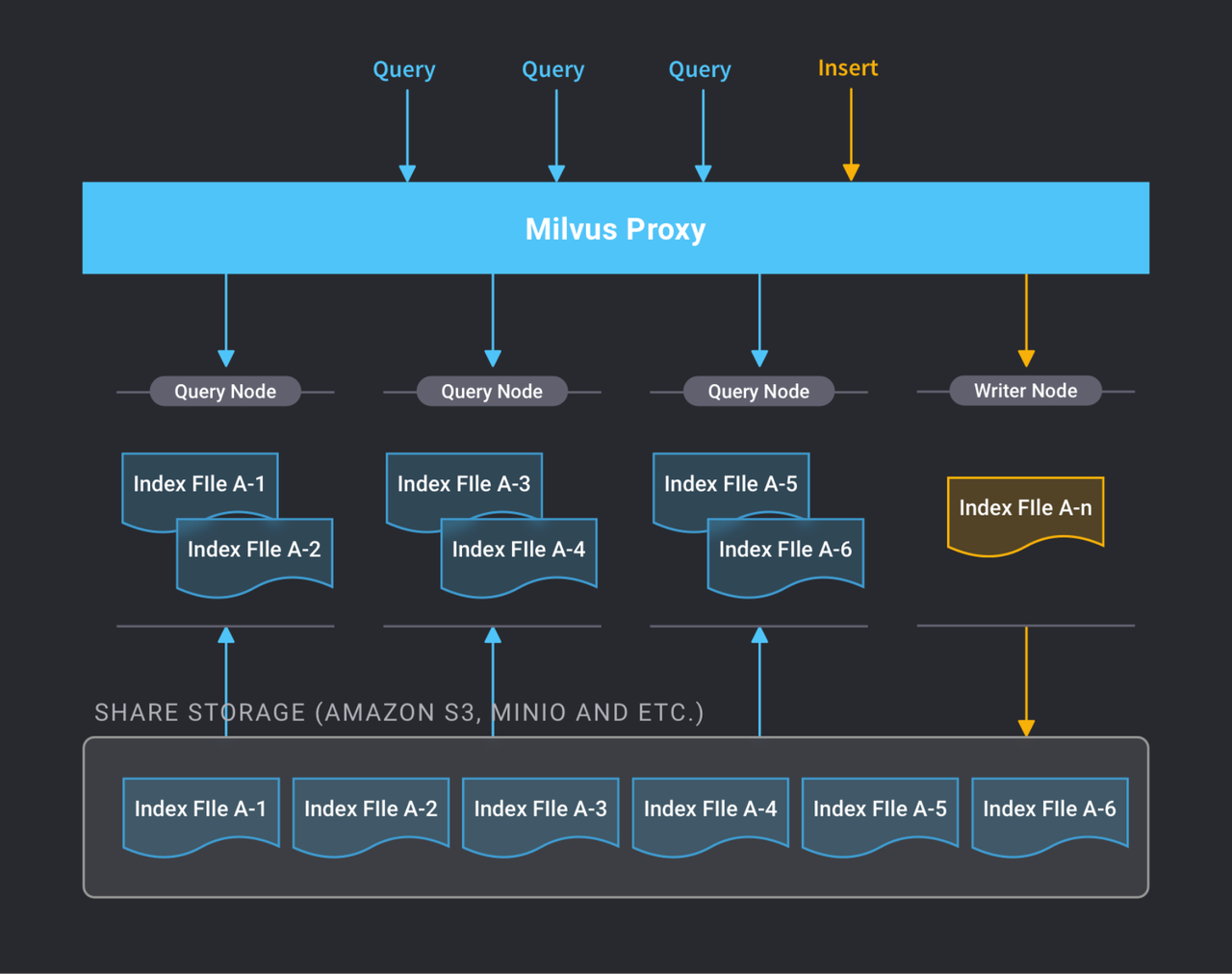
In Milvus 1.0, the R/W node has to take total care of the latest segment, including vector appending, searching in this unindexed segment, building index, etc. Since each collection only has one writer, the writer is very busy if the data is continuously streamed into the system. The performance of data sharing between the R/W node and the reader nodes is also a problem. Besides, we must either rely on NFS (not stable) or premium cloud storage (too expensive) for shared data storage.
These existing problems are hard to tackle in the Milvus 1.0 architecture. Thus, we have introduced new paradigms into the Milvus 2.0 design to resolve these issues.
Milvus 2.0: cloud-scalable vector database

Actor model
There are two models to program concurrent computation systems.
- Shared memory that means concurrency control (locking) and synchronous processing
- The actor model (AKA message passing) means message-driven and asynchronous processing
We can also apply these two models in distributed database clusters.
As stated before, most high-profile distributed databases use the same method: redo-log replication by consensus algorithms. This is synchronous processing using consensus algorithms to build a distributed shared memory for redo-log records. Different companies and venture capitals have invested billions of bucks in this technology. I didn’t want to comment on this until we started to work on Milvus 2.0. Many people regard this technology as the only way to realize distributed database systems. This is annoying. If I don’t say something, people might misunderstand that we were reckless in distributed database design.
In recent years, Redo-log replication by consensus algorithms has been the most overestimated database technology. There are two key issues.
- The presumption that redo-log replication is better is fragile.
- Vendors mislead people’s expectations on the capability of consensus algorithms.
Let’s say we have two database nodes, the source node, and the target node. In the ever beginning, they have the exact copy of the data. We have some change operations (I/U/D SQL statements) on the source node, and we want to keep the target node updated. What should we do? The simplest way is to replay the operations on the target node. But this is not the most efficient way.
Thinking about the running cost of an I/U/D statement, we can divide it into the execution preparation and the physical work parts. The execution preparation part includes the work of SQL parser, SQL optimizer, etc. No matter how many data records will be affected, it is a fixed cost. The cost of the physical work part depends on how many data records will be affected; it is a floating cost. The idea behind redo-log replication is to save the fixed cost on the target node; we only replay the redo-log (the physical work) on the target node.
The cost-saving percentage is the reciprocal of the number of redo-log records. If one operation only affects one record, I should see significant savings from redo-log replication. What if it’s 10,000 records? Then we should worry about the network reliability. Which one is more reliable, send the one operation or the 10,000 redo-log records? How about one million records? Redo-log replication is super in scenarios like payment systems, metadata systems, etc. In these scenarios, each database I/U/D operation only affects a small number of records (1 or 2). But it’s hard to work with I/O intensive workloads like batch jobs.
Vendors always claim consensus algorithms could provide strong consistency to the database clusters. But people only use consensus algorithms to replicate the redo-log records. The redo-log records are consistent on different nodes, but that doesn’t mean the data views on other nodes are consistent either. We have to merge the redo-log records into the actual table records. So even with this synchronous processing, we can still only get eventual consistency on the data views.
We should use redo-log replication by consensus algorithms in the appropriate places. The metadata system (ETCD) and messaging platform (e.g., Apache Pulsar) used in Milvus 2.0 have implemented consensus algorithms. But as I said before, “for the Milvus vector database, we don’t find enough incentives for being a state machine replication group as a whole.”
In Milvus 2.0, we use the actor model to organize the worker nodes. The worker nodes are lonely. They only talk to the messaging platform, getting commands and sending results. It sounds boring.
“What is our motto?" “Boring is always best.” – The Hitman’s Bodyguard (2017)
The actor model is asynchronous. It is suitable for scalability and availability. Since the worker nodes don’t know each other, there is no impact on other worker nodes if some of the worker nodes join or are removed.
Separation of availability and durability
In Milvus 2.0, we do operation replay rather than log replay, because in the vector database, there is not much difference between operation replay and log replay. We don’t have the Update function nor the Insert with Select function. And it’s also much easier to do operation replay with the actor model.
So multiple worker nodes might execute the same operation from the messaging platform according to their responsibility. I mentioned before we decided to use the S3 cloud storage as the shared storage layer of the Milvus database cluster. The S3 storage is very reliable. Then is it necessary for different worker nodes to write out the same data to the shared storage?
Thus we designed three roles for the worker nodes.
- The query node maintains an in-memory data view according to the assignment. The work of the query node includes doing vector search and keeping the in-memory data updated. But it doesn’t need to write anything to the S3 storage. It is the most memory-sensitive node in the group.
- The data node is responsible for writing the new data to the S3 storage. The data node doesn’t need to maintain the in-memory data view, so the hardware configuration of the data node is quite different from the query node.
- The index node builds indexes for the segments closed by the data node when the size of the segments reaches the threshold. This is the most CPU-intensive work in the group.
These three types of nodes represent different kinds of workload. They can scale independently. We call it separation of availability and durability learned from the Microsoft Socrates cloud database.
The end, also the beginning
This article has reviewed several design decisions of Milvus vector database 2.0. Let’s quickly wrap up those points here.
- We have chosen the eventual consistency for Milvus cluster 2.0.
- We have integrated the mature cloud components into Milvus 2.0 as much as we can. We have controlled the new components introduced by Milvus 2.0 into users' production environments.
- By following the actor model and separation of availability and durability, Milvus 2.0 is easy to scale in the cloud environment.
So far, we have formed the backbone of the Milvus 2.0 cloud-scalable database, but our backlog contains many requirements from the Milvus community that need to be satisfied. If you have the same mission (“Build more open-source infrastructure software to accelerate the AI transformation”), welcome to join the Milvus community.
Milvus is a graduation project of the LF AI & Data foundation. You do NOT need to sign any CLA for Milvus!
Appendix
Milvus design doc
https://github.com/milvus-io/milvus/tree/master/docs/design_docs
Raft implementation in C++
If you are still interested in the consensus algorithm, I suggest you check eBay’s open-source project Gringofts. It’s a C++ implementation of the Raft consensus algorithm (a variant of the Paxos family). My friend Jacky and Elvis (my ex-colleagues at Morgan Stanley) built it for the eBay online payment system, which is precisely one of the most suitable scenarios for this technology.